Language Accessible Conversation Technology: A Work In Progress


August 17, 2021
Cortico’s mission of amplifying under-heard voices provides a sense of urgency to the issue of language accessibility. We have a way to go to reach our goal of providing a seamless experience for speakers of diverse languages. Ultimately, we are building a tool that supports listening and understanding the perspectives voiced by under-heard communities, including historically marginalized language groups.
There are many engineering and design challenges to tackle along the way to this goal, and in this post we will describe how this work has unfolded to date. It began soon after we launched the English-only pilot of Local Voices Network in 2019 – with a goal of visualizing conversation data and making it searchable. Within a year, our first Spanish-language conversation was convened and it became clear that we would need to make changes to our data pipeline in order to include more languages.
Our speech pipeline automatically sends every conversation over to Google’s Speech API for initial automated transcription. It was pretty simple to add a language code to send over to Google— before we always sent “en-US” for English, so we added the ability to also send “es-US” for Spanish. We store language codes as an array of strings, to allow for the case of bilingual speakers switching between languages.
After automatic transcription, our pipeline sends the same audio file through a human transcription process. Eventually, these conversations end up on our site with Spanish transcripts. However, the site as a whole was still stuck in English.
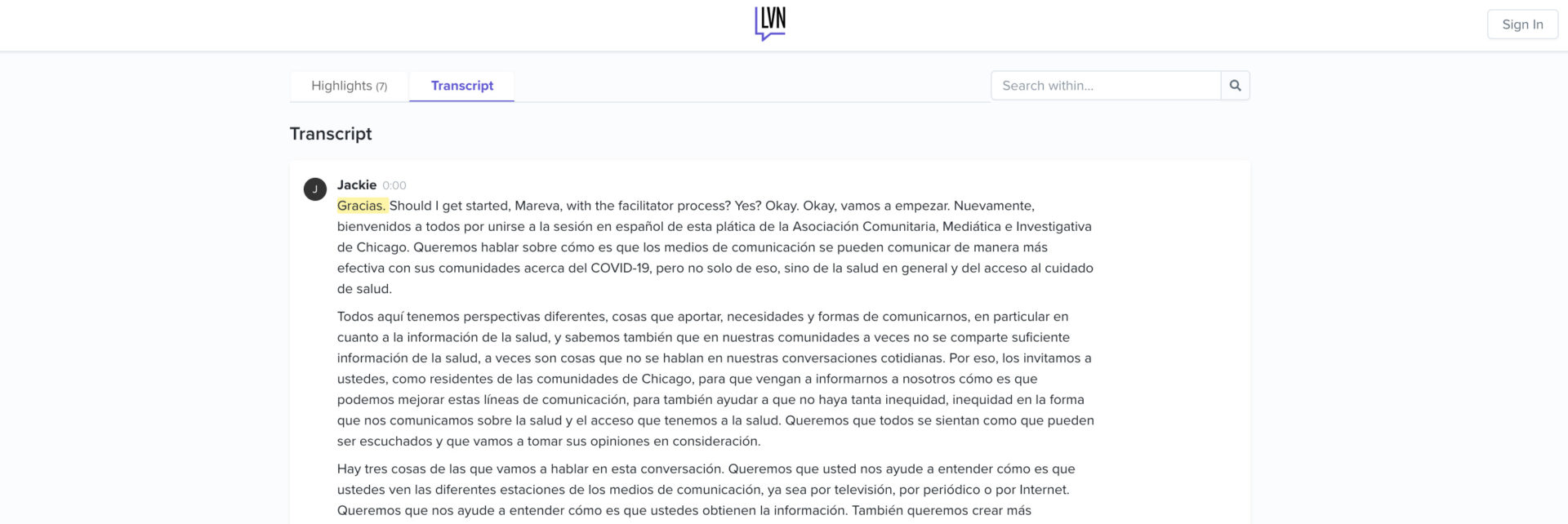
Though the transcript text is in Spanish, the tab labels and other copy are still in English. So even though our data pipeline allowed for Spanish, our site as a whole was still prioritizing English.
This summer, we began the process of internationalizing our site. An overwhelming majority of internet users world-wide use a non-English language online. Even though we currently only operate in the United States, the communities we work with are often diverse in terms of language. If we truly want to surface underheard voices, we need to support as many languages as possible.
Multi-language support is still in the works, but our next steps will:
Our goal is for the site to be able to switch between English and Spanish by the fall.
Though this effort will make much of the site more usable, it will not translate the transcripts themselves. This is an ongoing research effort for us. Our transcript display is powerful in that we can highlight words as they are spoken and also create highlights from the full transcript . We are able to do this by having each word in a transcript assigned a time at which it was spoken in the conversation. However, this becomes more difficult since translations capture meaning at the phrase or sentence level, not word for word, and so the timings will need to be adjusted.
Ideally, we will one day be able to toggle the transcript between different languages so that users can read conversations in their native language while hearing the conversations in the participants’ voices.
Another area for growth is topic analysis, which is currently trained on English transcripts.

Ideally, if we were to look at this English conversation in Spanish, we would see the keywords translated into Spanish as well. Furthermore, if a conversation takes place in Spanish, we would be able to send it to a model trained on Spanish transcripts to better surface keywords.
We’re excited to ship a version of the product that will enhance the ability to surface insights and themes from conversations hosted in Spanish this fall. And, we look forward to the day when our platform will more seamlessly amplify the voices of historically under-heard voices from diverse language communities.