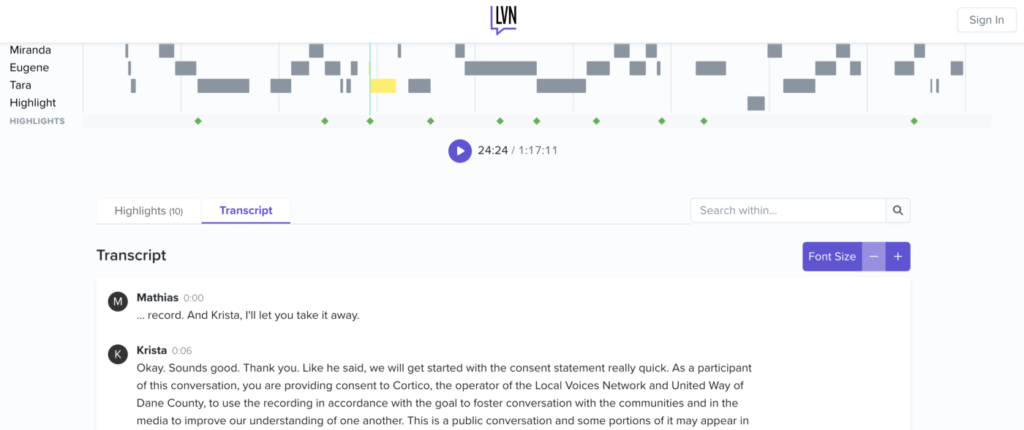
Building a transcript editor for the web
Cortico’s mission of bringing underheard voices to the center of a stronger dialogue means we have a lot of transcribed words. Though we run two passes of transcription (one automated transcription via AssemblyAI and one human transcription via Rev), with over 14 million words in our corpus, there are always a good chunk of words that will be mis-transcribed. Sometimes this is because of ambient noise, a misspelled name, or location specific words that only a local would know (i.e. the name of an elementary school).
Now that we’ve worked with over 65 partner organizations to convene and make sense of nearly 2,000 hours of audio data, it has become clear we need a way to give our partners the ability to make edits to their transcripts. So we’ve spent the past few months on the technically challenging problem of building a ✨ transcript editor ✨.
A simplified version of Cortico’s data pipeline looks like:
5. We save the transcripts as “snippets” in our database
6. We display the transcript for members of LVN to read, listen, and make highlights which can then be shared.
We knew that building out a proper transcript editor would require a big backend refactor, so two years ago we decided we would handle transcript corrections manually until we hit enough scale where it would no longer be feasible. During the manual phase, to correct a transcript, our flow looked like:
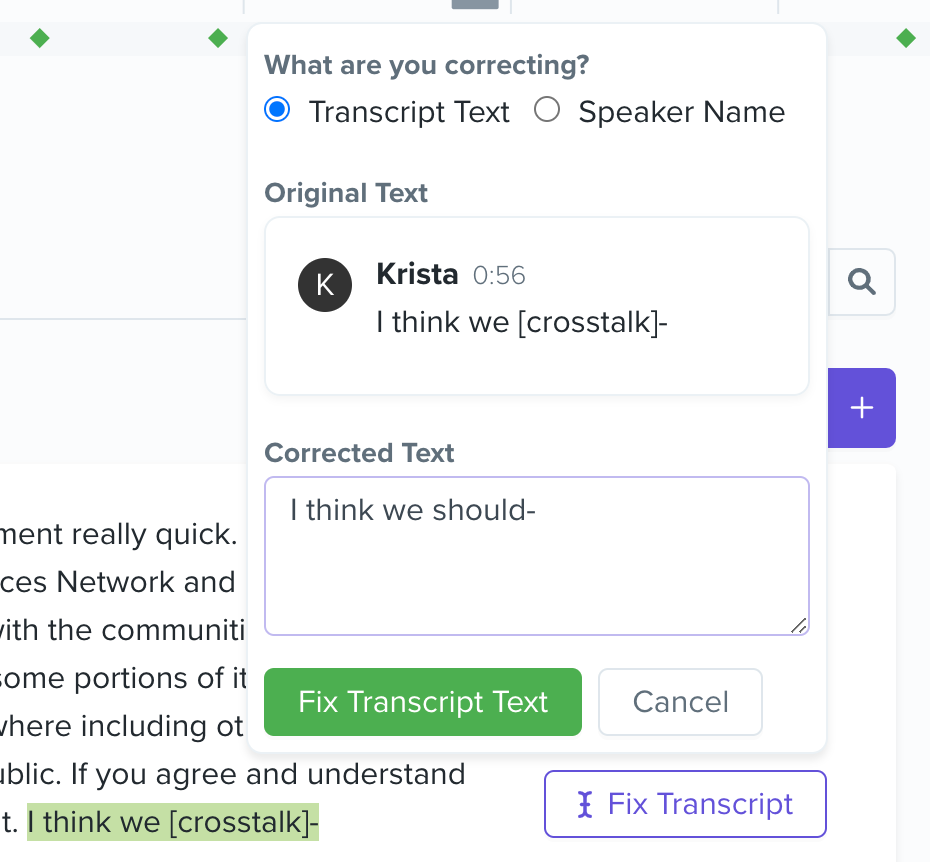
This flow was slow to update and put a lot of manual labor on Kelly. We’re excited that now that we have enough conversations flowing through the product, we can justify building our own transcript editor and making everything easier for both Kelly and our partners!
Building a transcript editor required a large amount of frontend, backend, and pipeline work for the team. We’ll write about the different parts in more detail in separate posts, but this post will serve as an overview of the problem in general. Here are just some of the problems we had to face:
transcript_edits table which has a unique constraint on version number and conversation id. When the frontend submits a request, it attempts to increment the version number. If that version number already exists in the database, a constraint error is thrown, and the user is asked to refresh the page. This way the transcript that the user sees is always up to date.snippets table, doing an insert or delete could potentially mess with our IDs, and so we needed a different way of ordering them, via a column index_in_conversation .Very fortunately for us, the transcript editor problem is not an entirely new one. We learned a lot from going through the source code of BBC’s React Transcript Editor and at first thought we would implement ours in a similar way. Their library uses Draft.js, a framework for text editing created by Facebook. However, one of their pinned issues was about poor performance in audio over an hour long. This was a big deal for us as almost all of our conversations are over an hour long.
Luckily the fine engineers over at the BBC also tried out building a transcript editor with similar features using Slate, a different, less opinionated text editing library. Slate is still in beta, but its performance proved a lot better both in the BBC’s example as well as in our own Storybook tests. Slate was also much easier to pick up since it did not require you to learn all of Draft.js’ models, and you can use whatever schema you want.
We are so grateful to these open source libraries which helped us out. To give back, one of the features we didn’t find in these libraries was a find/replace feature. So we published our own method of doing this. The code can be found here, and a demo here.
The BBC wrote up a good summary of this problem in their repo notes, but it basically comes down to:
[
{ word: "Welcome", start: 0, end: 0.5 },
{ word: "to", start: 0.5, end: 0.6 },
{ word: "this", start: 0.6, end: 0.8 }
...
]
amazing. This isn’t the worst problem—we can do a linear interpolation, for example.We split our small but mighty team into a few streams of work:
It took pretty much all of the first quarter of 2022 for our team to build this out, but we are so excited to roll it out to our partners and give them better control over their data. We’re very pleased with how it has turned out, and had fun working on this challenging problem.
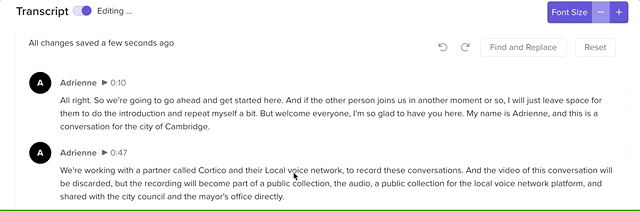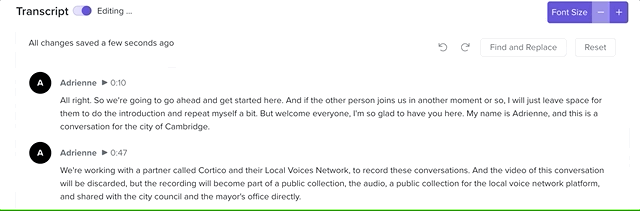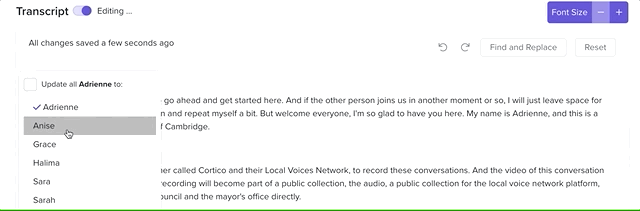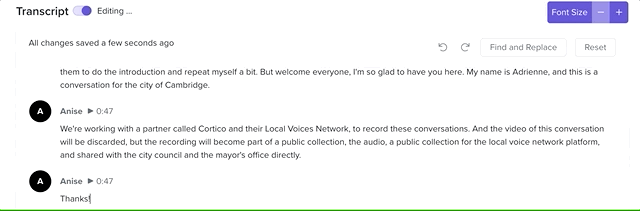
The transcript editor in action!
