Introducing Topic-Based Insights
Here at Cortico we’re closing in on ✨1000✨ conversations held since we launched LVN in 2019! We’re grateful for all of the volunteers and partners who have helped us reach this milestone, but most importantly we’re honored that so many people have chosen to share their perspectives and lived experienced with us, their neighbors, and the greater LVN community.
Our technology is built to capture, make sense of, and amplify these stories. We believe that recorded speech, the voice of a conversation participant, is an incredibly intimate and powerful way to understand someone else’s perspective. To that end, one of the key design challenges in our technology product is driving understanding of an increasing array of perspectives while maintaining a connection to each individual voice in the chorus.
At the level of an individual conversation, we provide tools grounded in natural language processing to automatically surface salient or notable terms used in the discussion. In addition, participants are invited to return to their conversations to lift up moments of meaning through the creation of highlights, an essential ingredient in building community-powered understanding.
Zooming out from a single conversation, however, we’re presented with a very real problem. With a single collection of conversations being 10s or 100s of hours of speech, how can we help people get a general sense for what’s being discussed in a collection in less time than it would take to listen to all of that audio?
In the nearly limitless list of amazing stuff that can be built in this space, we’ve jumped in with a first step. We’ll soon be releasing our first feature that approaches the problem of sense-making across a collection of conversations: topic-based insights.
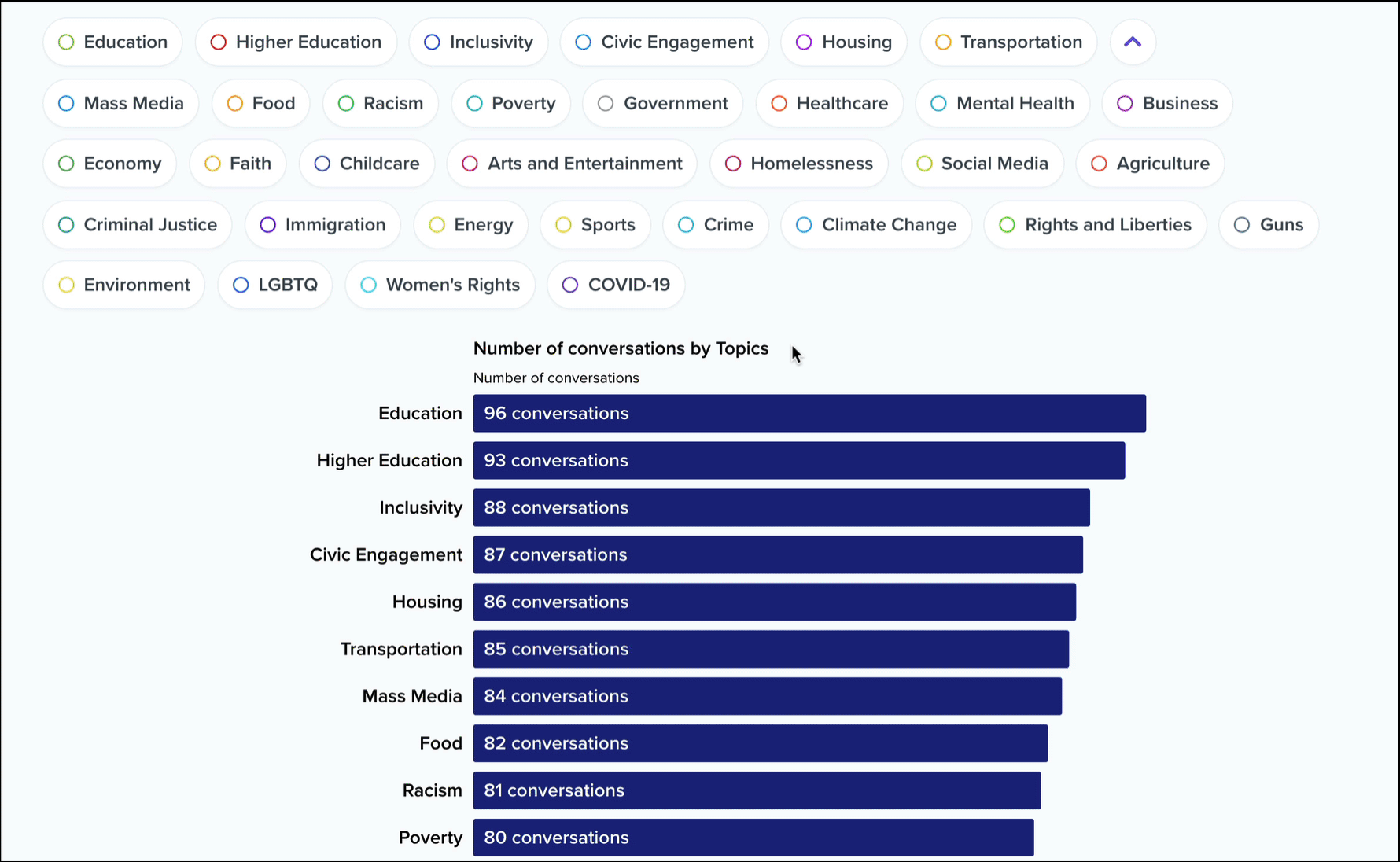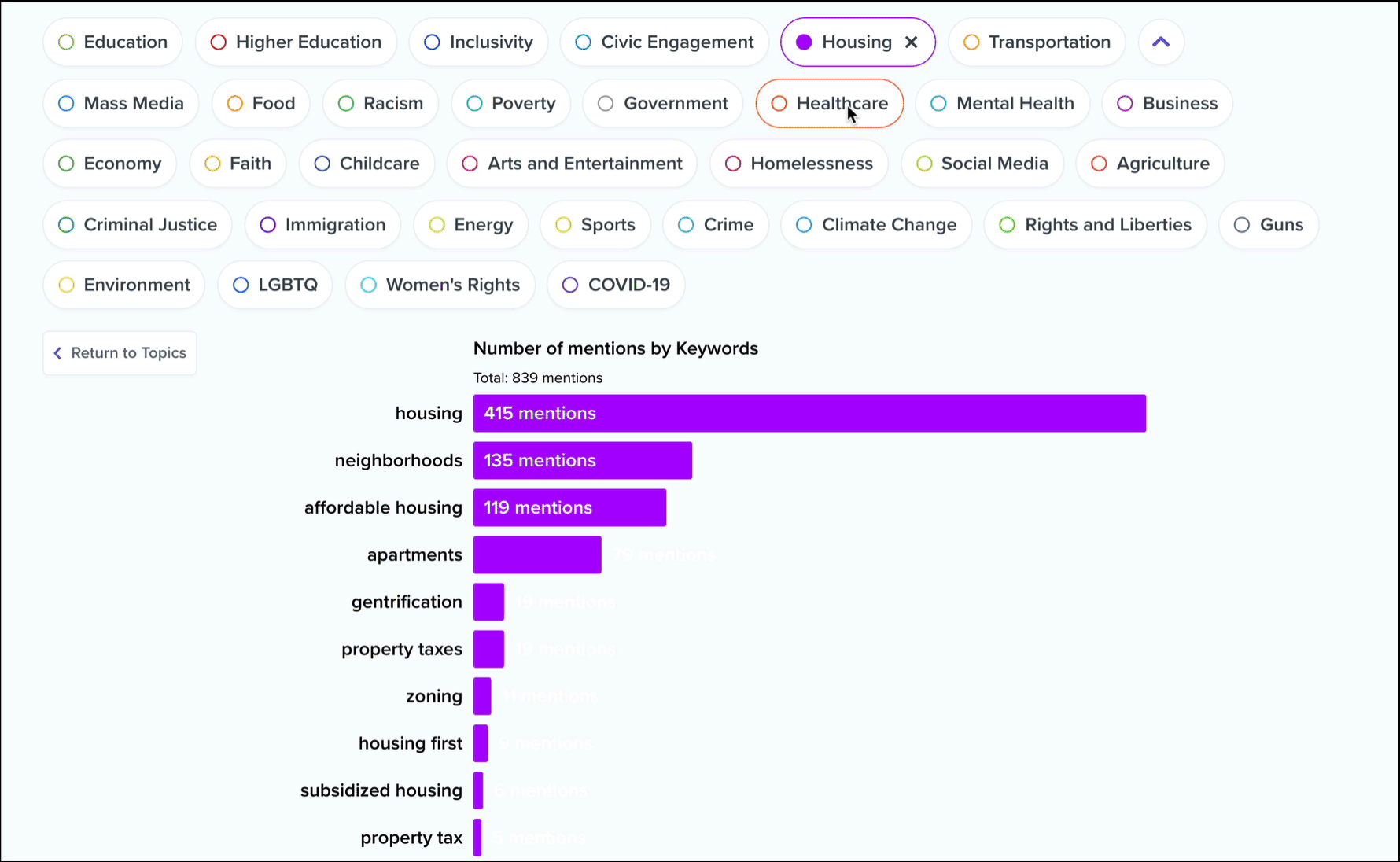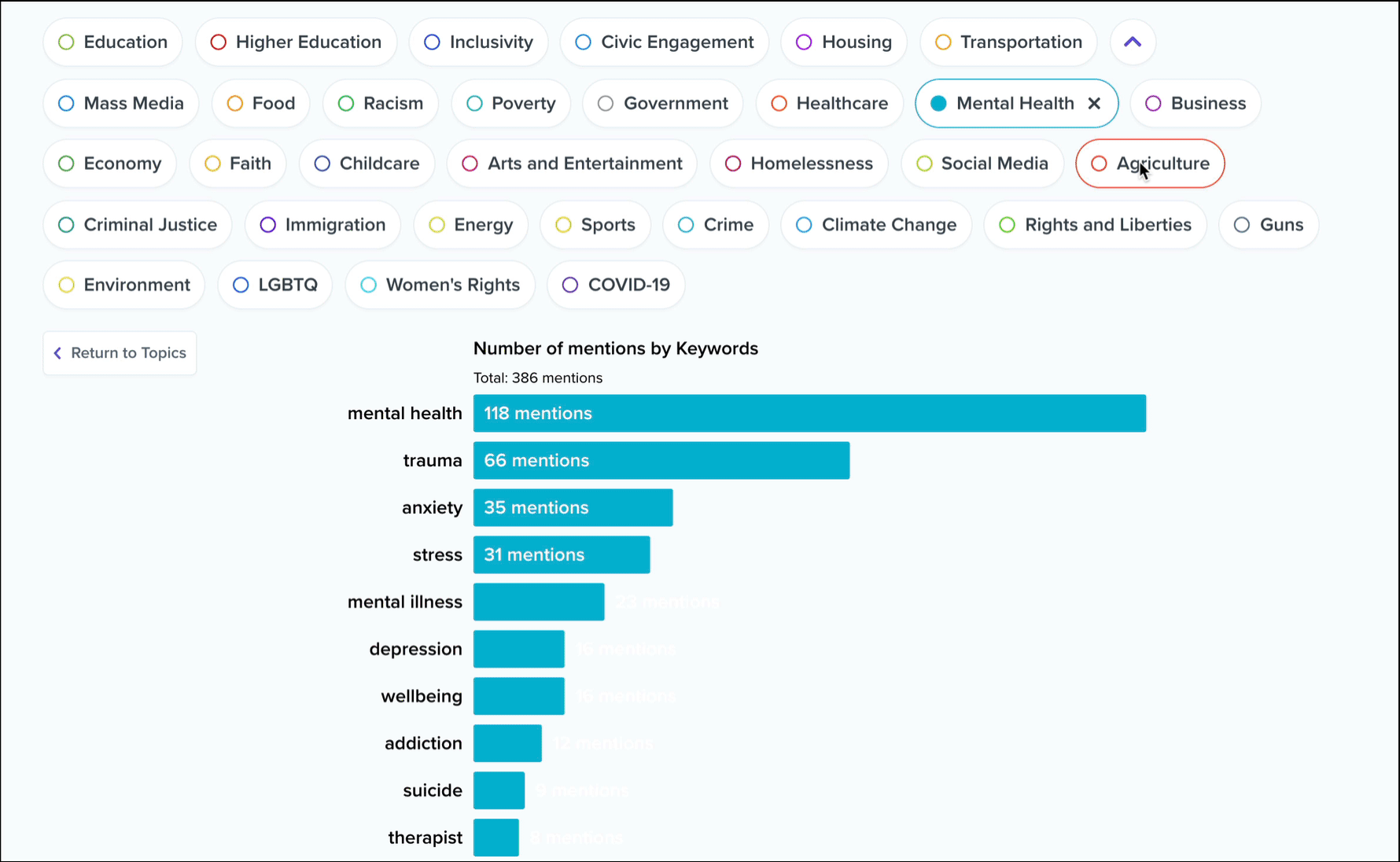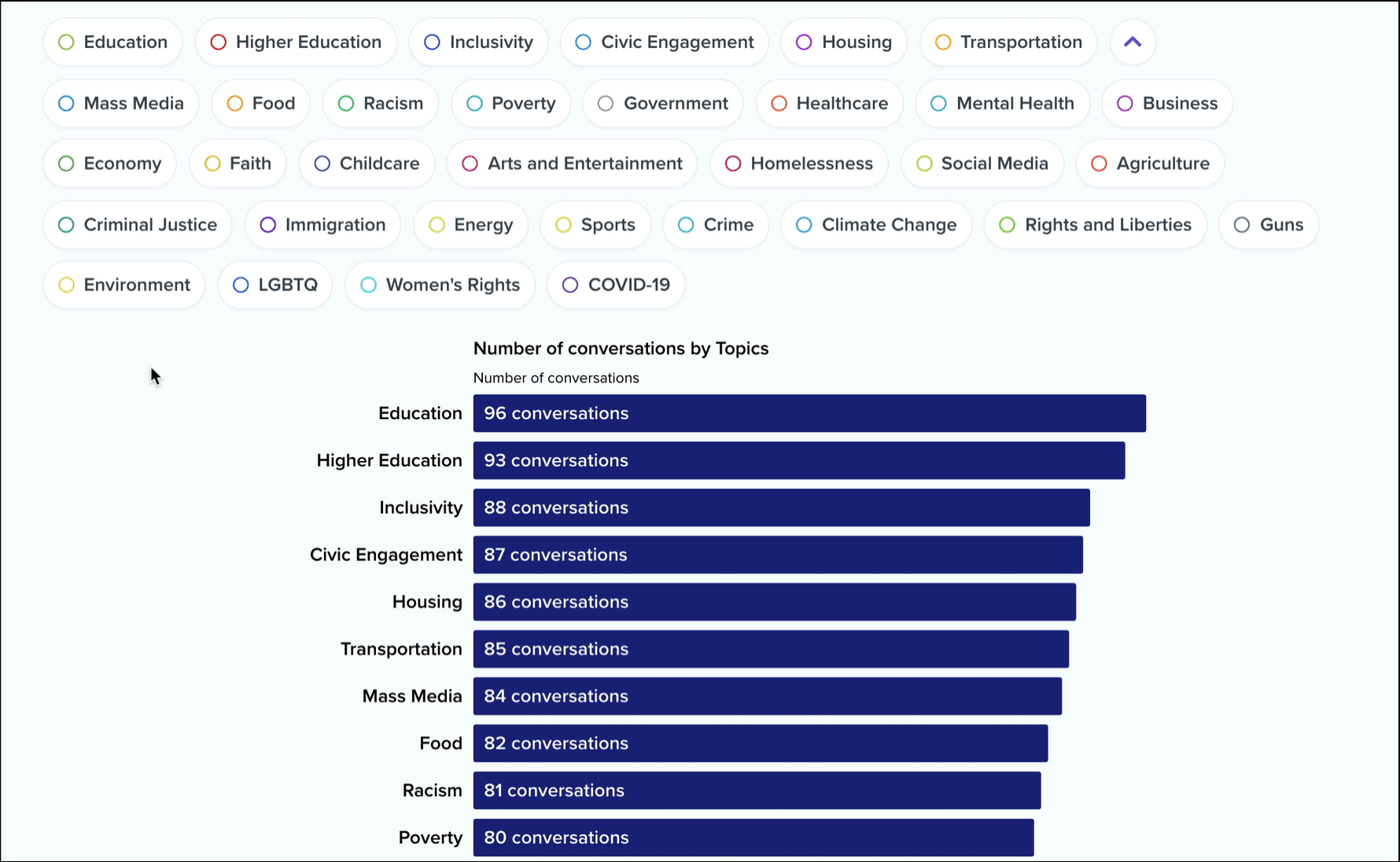
For each collection on the platform, we surface a list of topics ranked by the number of conversations in which they occur. For example, here’s that list for our Madison pilot collection.
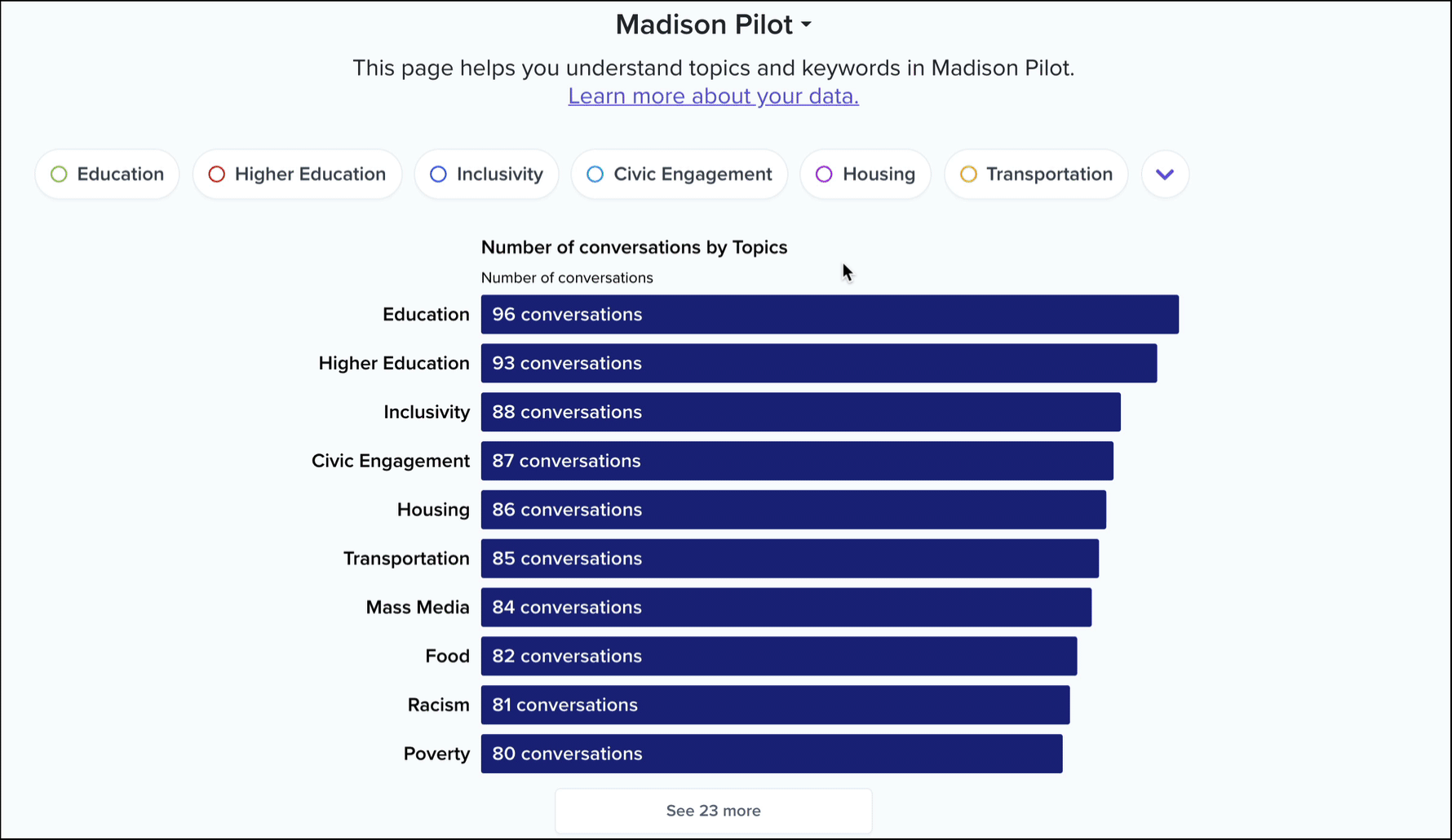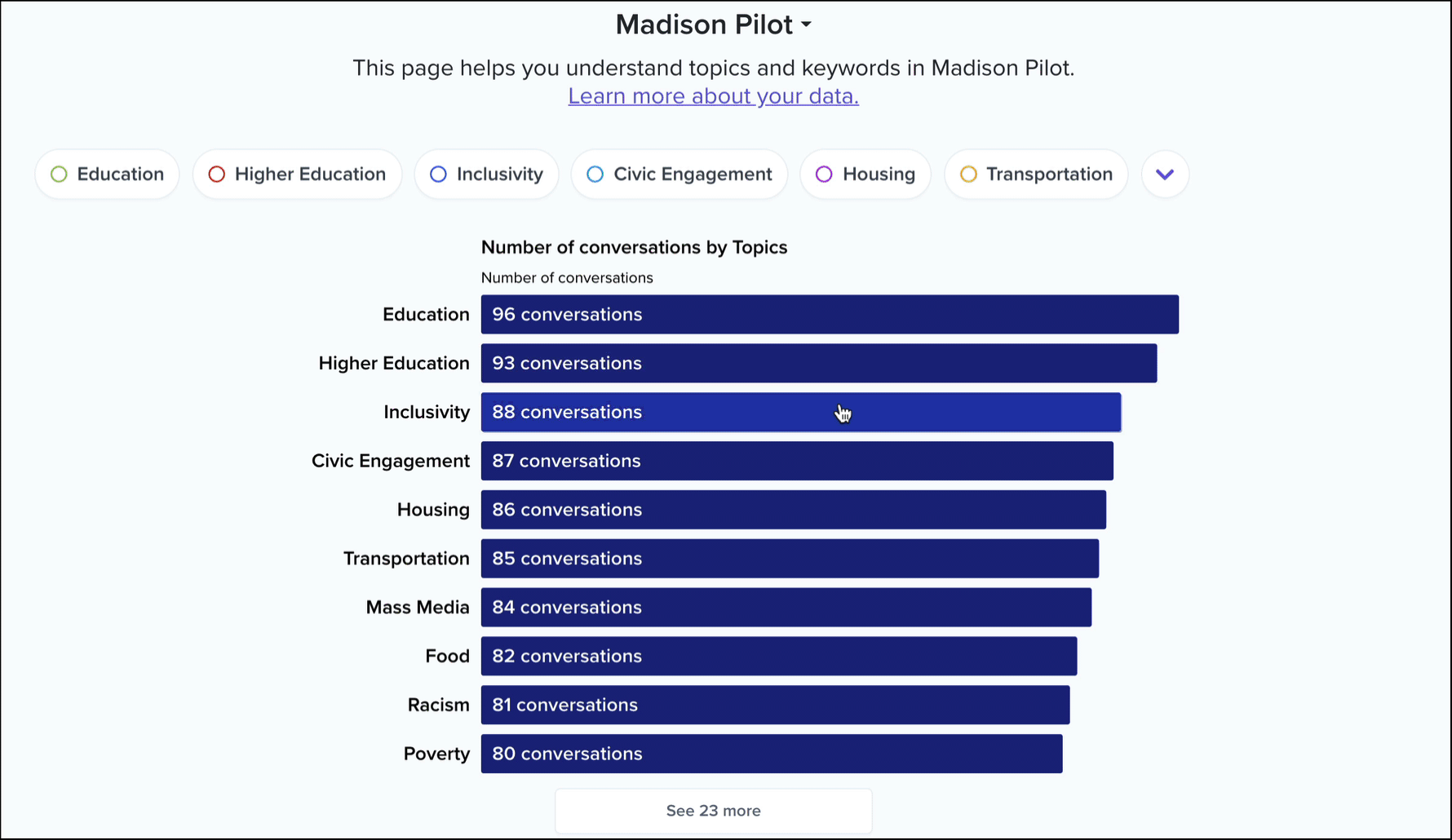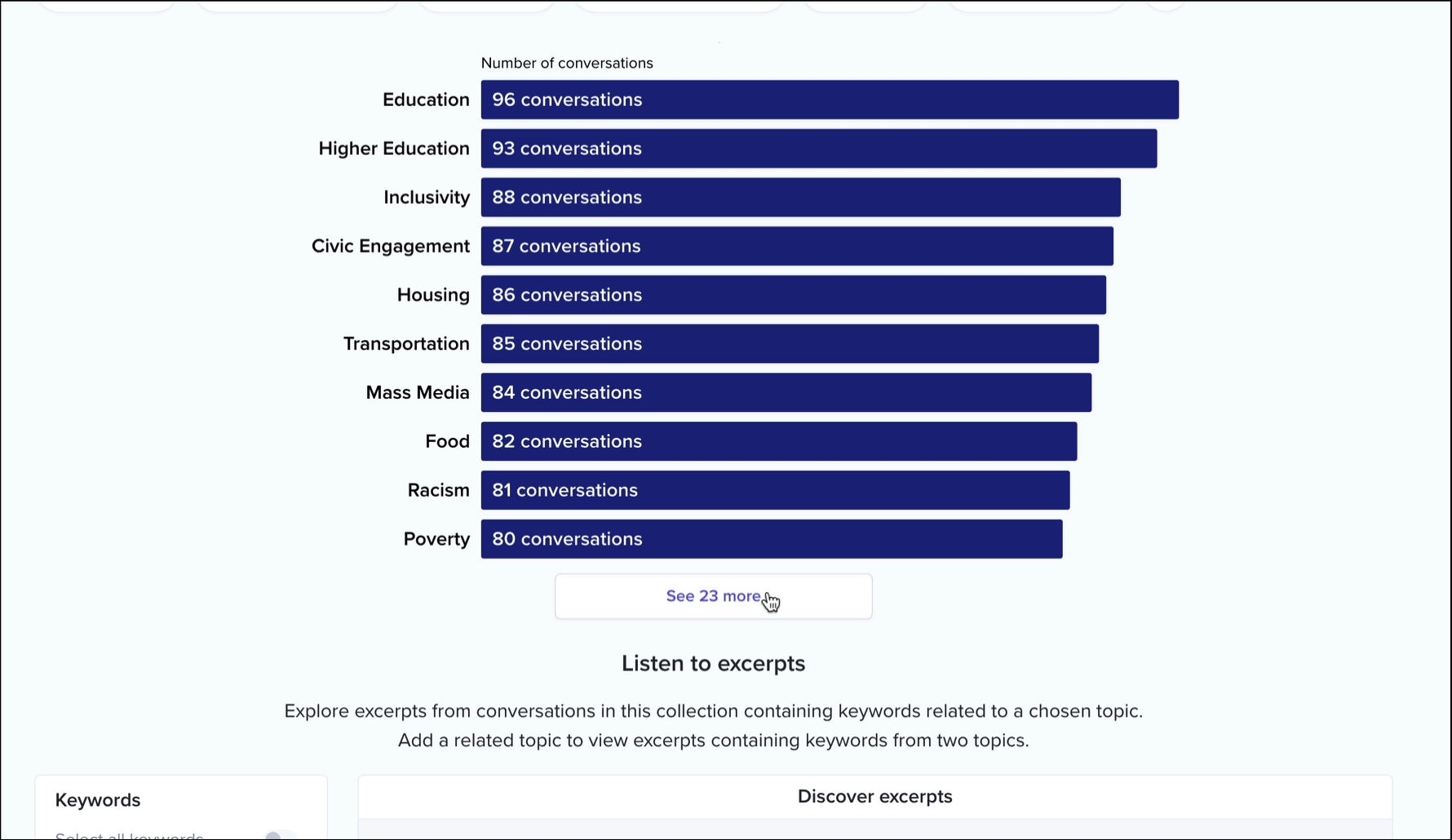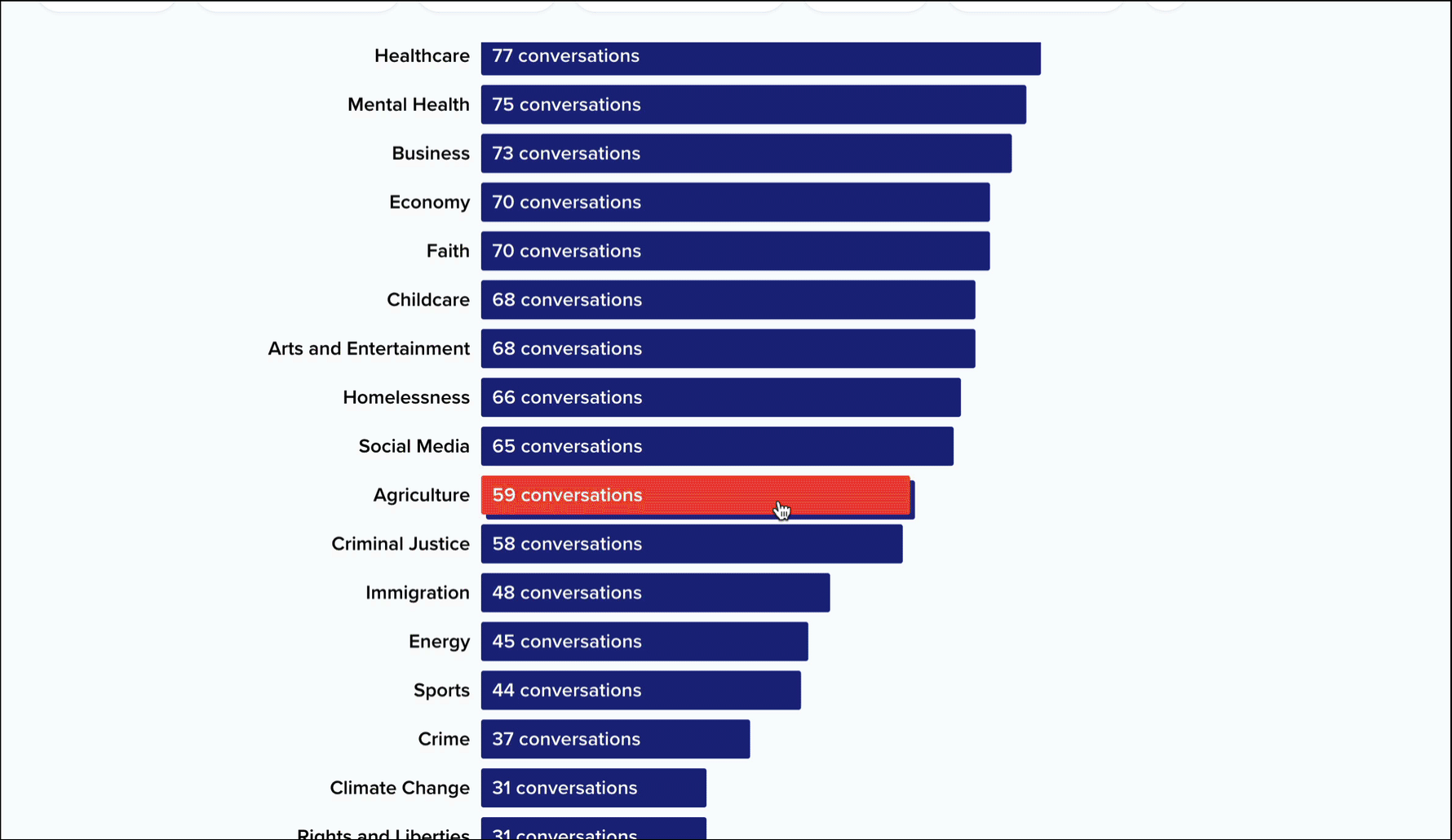
These topics are curated by our staff and composed of a large list of keywords that have been algorithmically generated and manually reviewed by our team.
As with any product feature that leverages machine learning, there’s a very real bias problem. Each member of the team brings their unique lived experiences and value systems with them to the job. How can we ensure that systems like these are designed equitably? As a starting place, our topic working group encompasses a broad swath of the team, spanning all of our disciplines and areas of expertise, from software engineering to community activism. We’ll be making our full topic and keyword classifications publicly available on GitHub, and will be inviting feedback directly in the product to leverage the expertise of our user-base. In the future, we’re planning to make it possible for partners to create their own custom topics for conversation analysis.
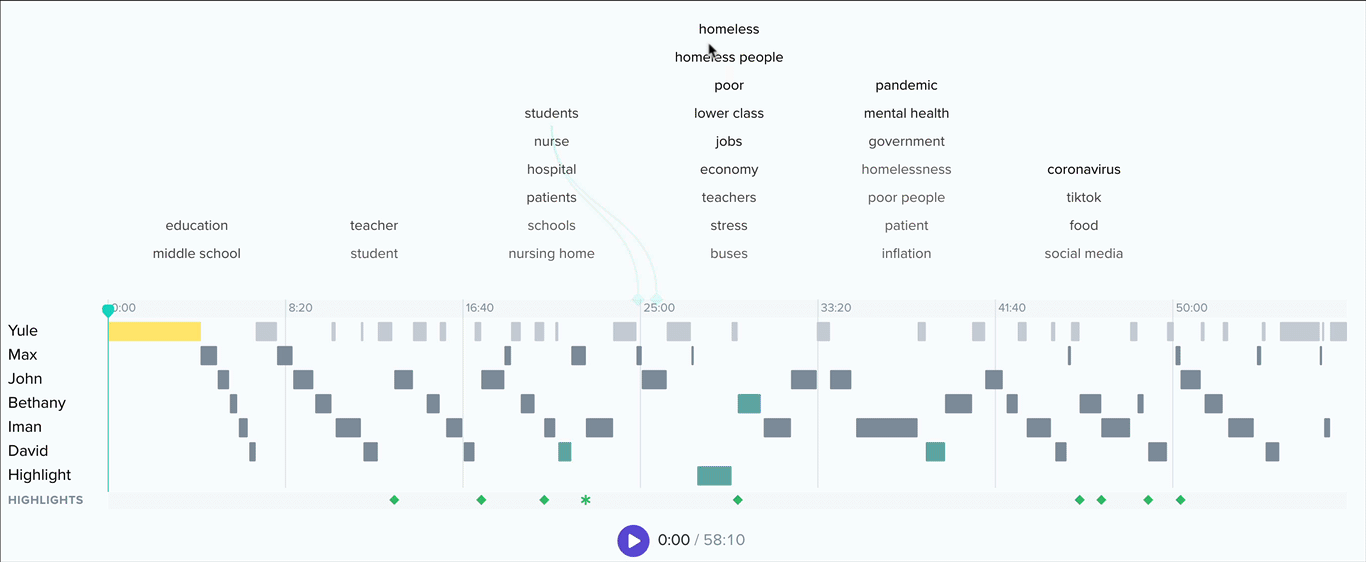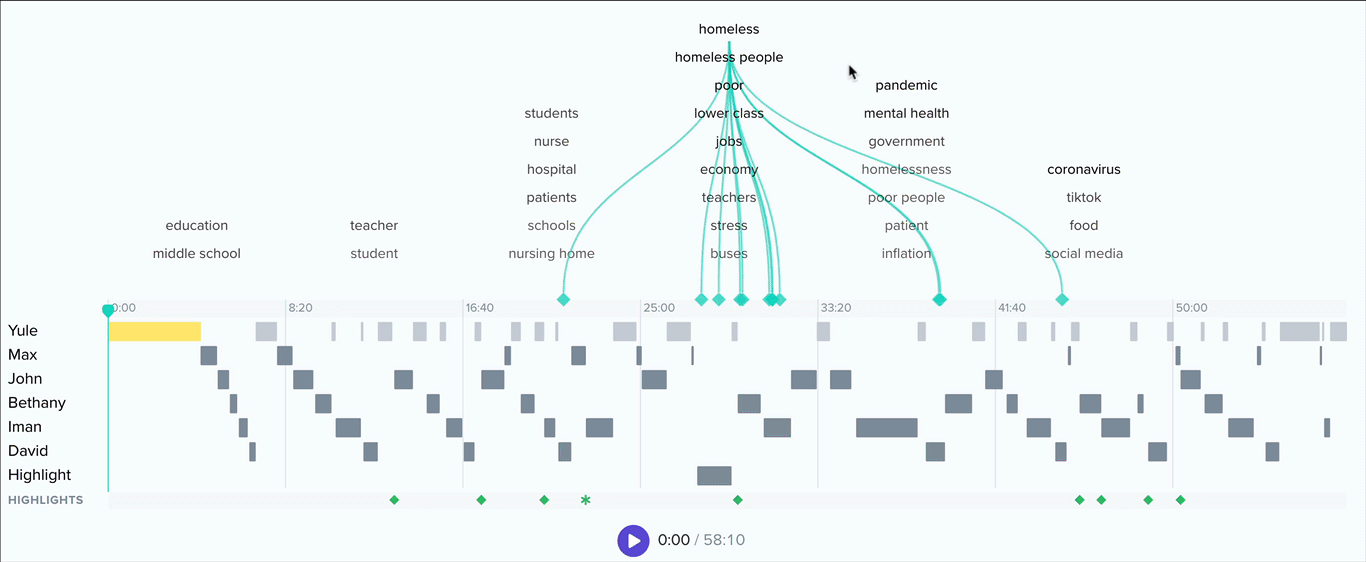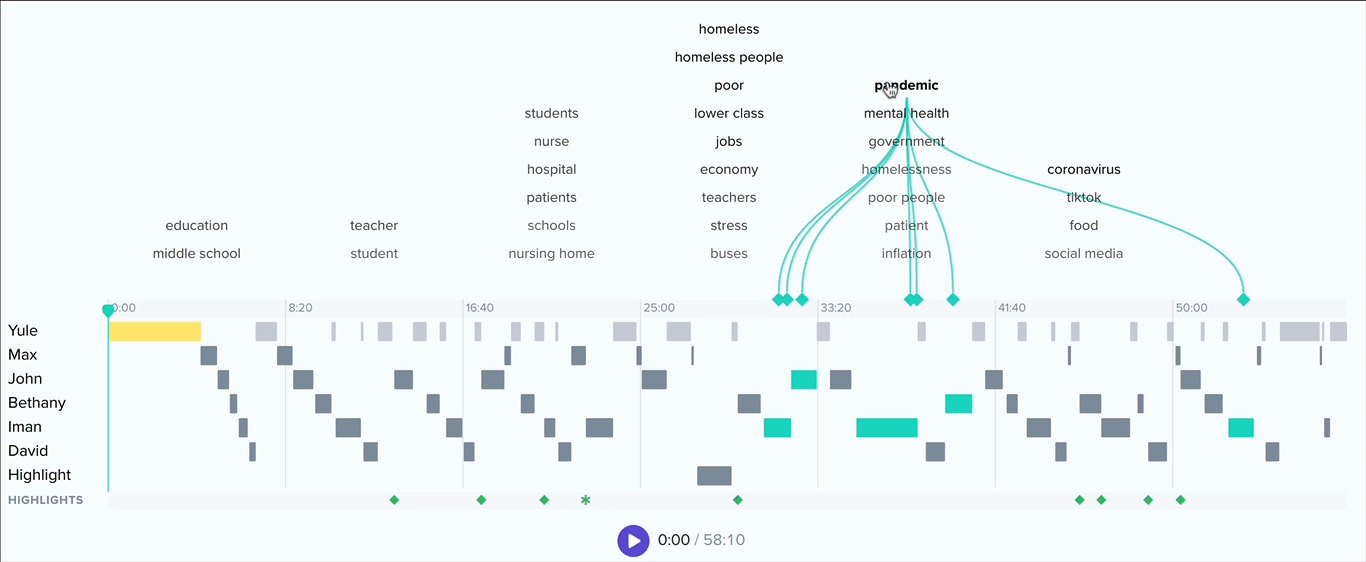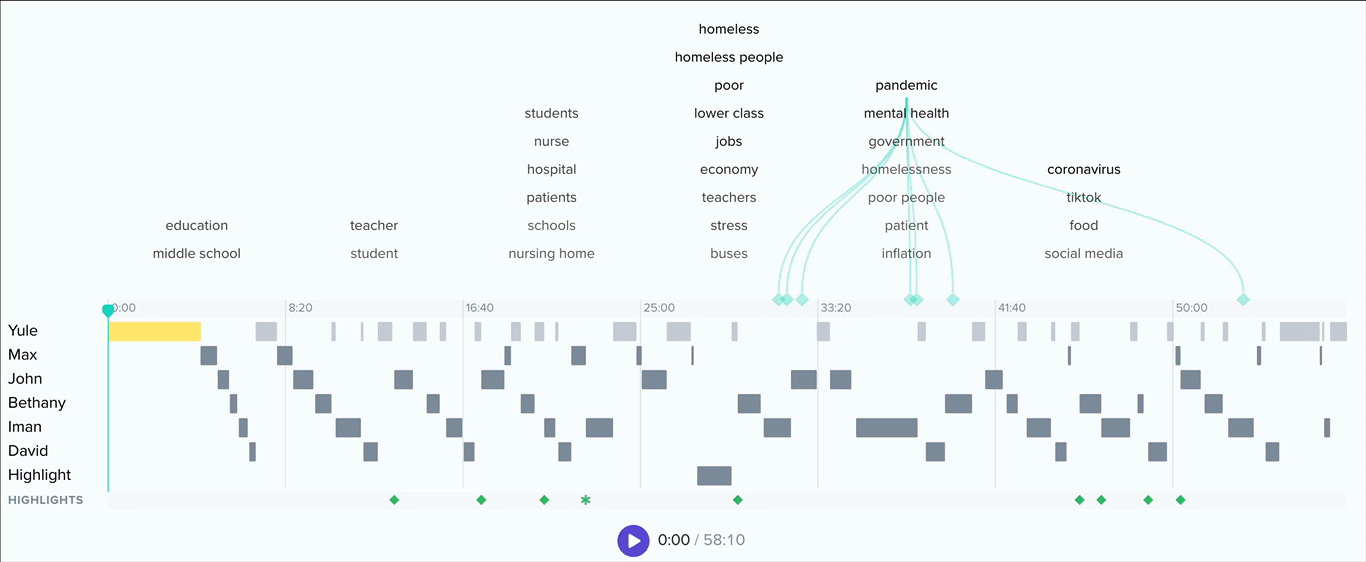
Clicking into a topic will update the chart to show which keywords within that topic have the most mentions. Ok, but where are these topics and keywords coming from? Below this bar chart, you’ll see an interactive list of conversation excerpts.
These are ranked by the number of keyword mentions from the selected topic, with each excerpt typically encompassing 30 to 120 seconds of audio from a single conversation participant. In essence, these are the individual voices that are driving this topic data. As with all of our interactive transcripts, you can click anywhere in the transcript to start playback immediately from a chosen word, and we’ve included a keyword filter to help you sift through the list.
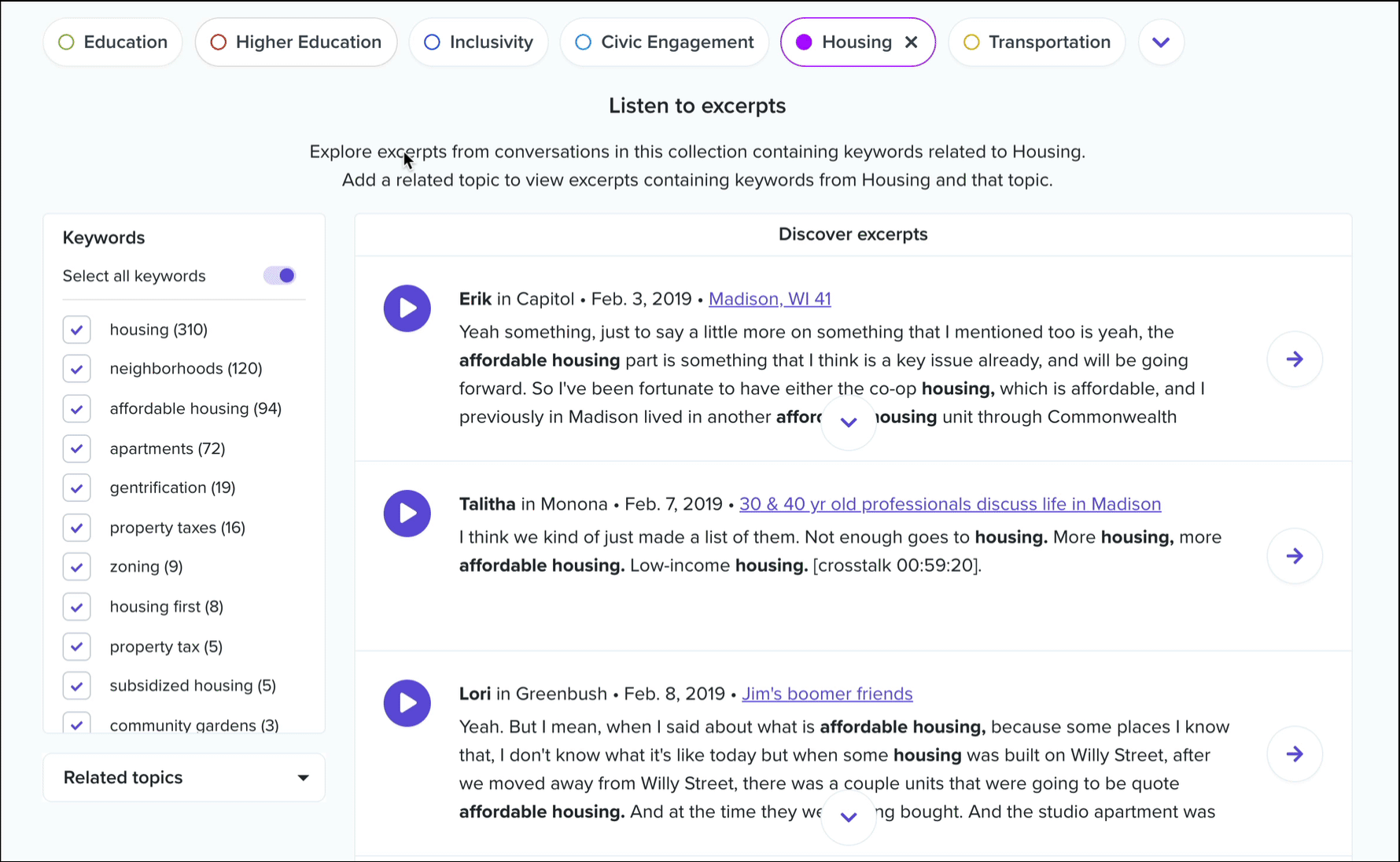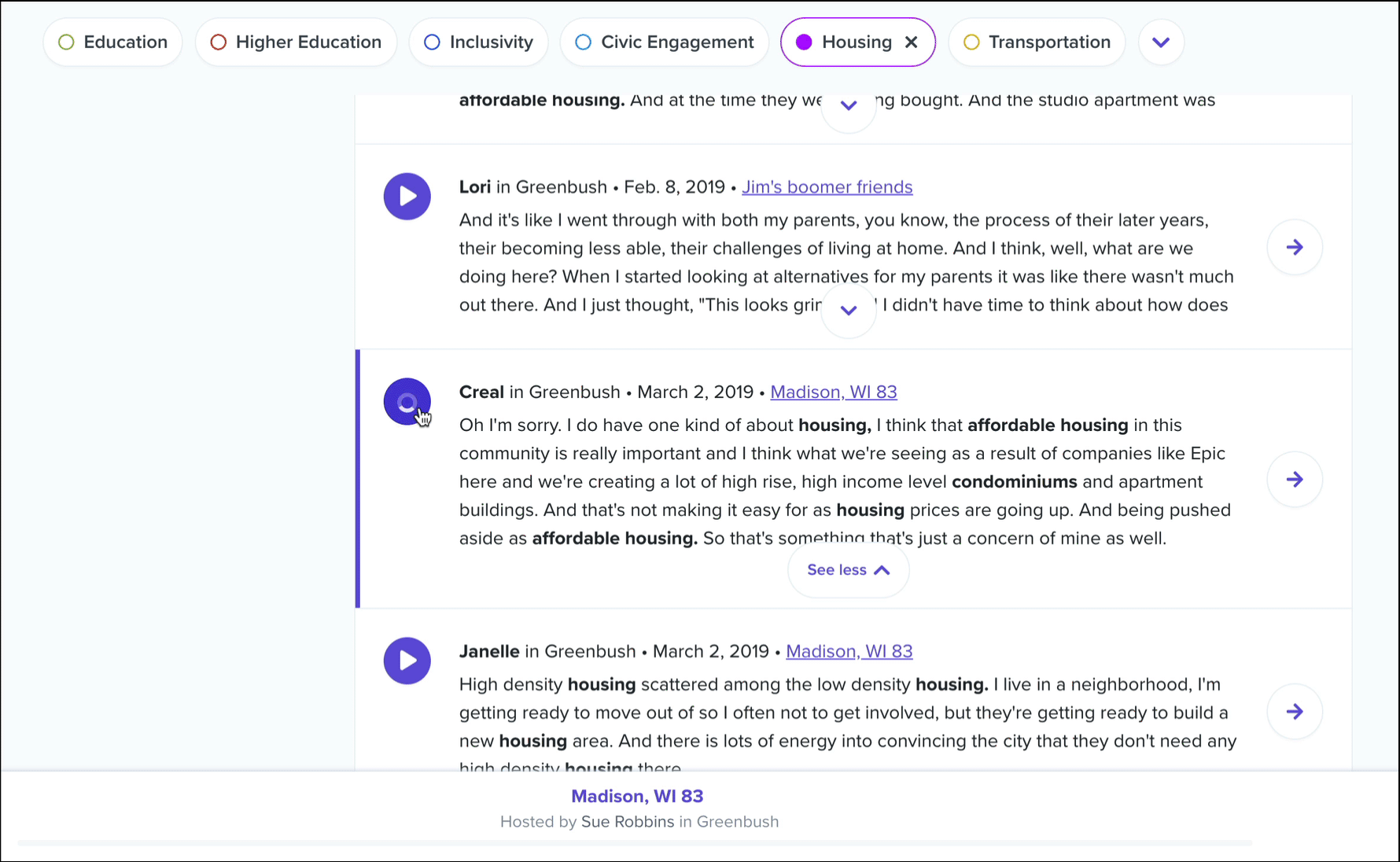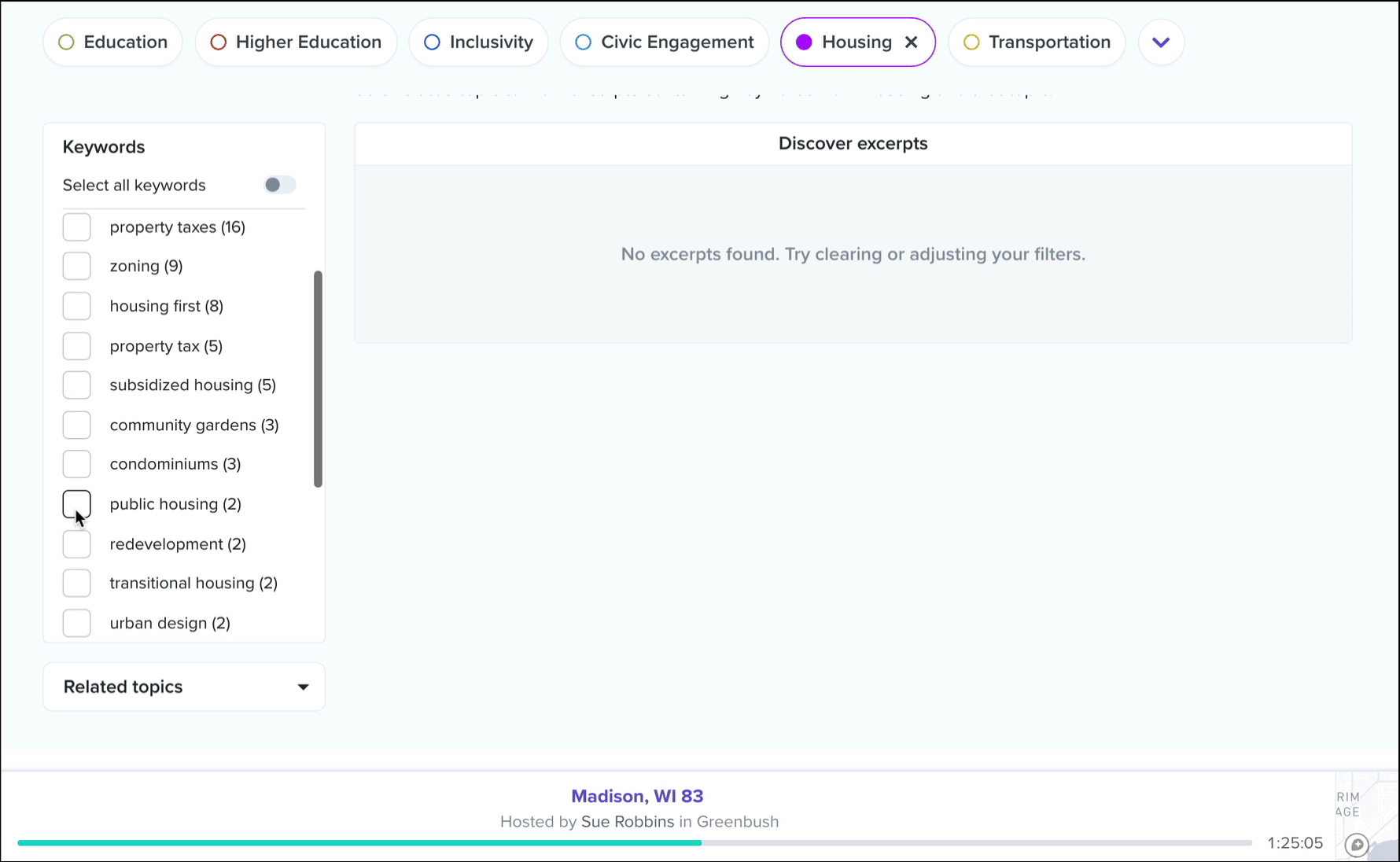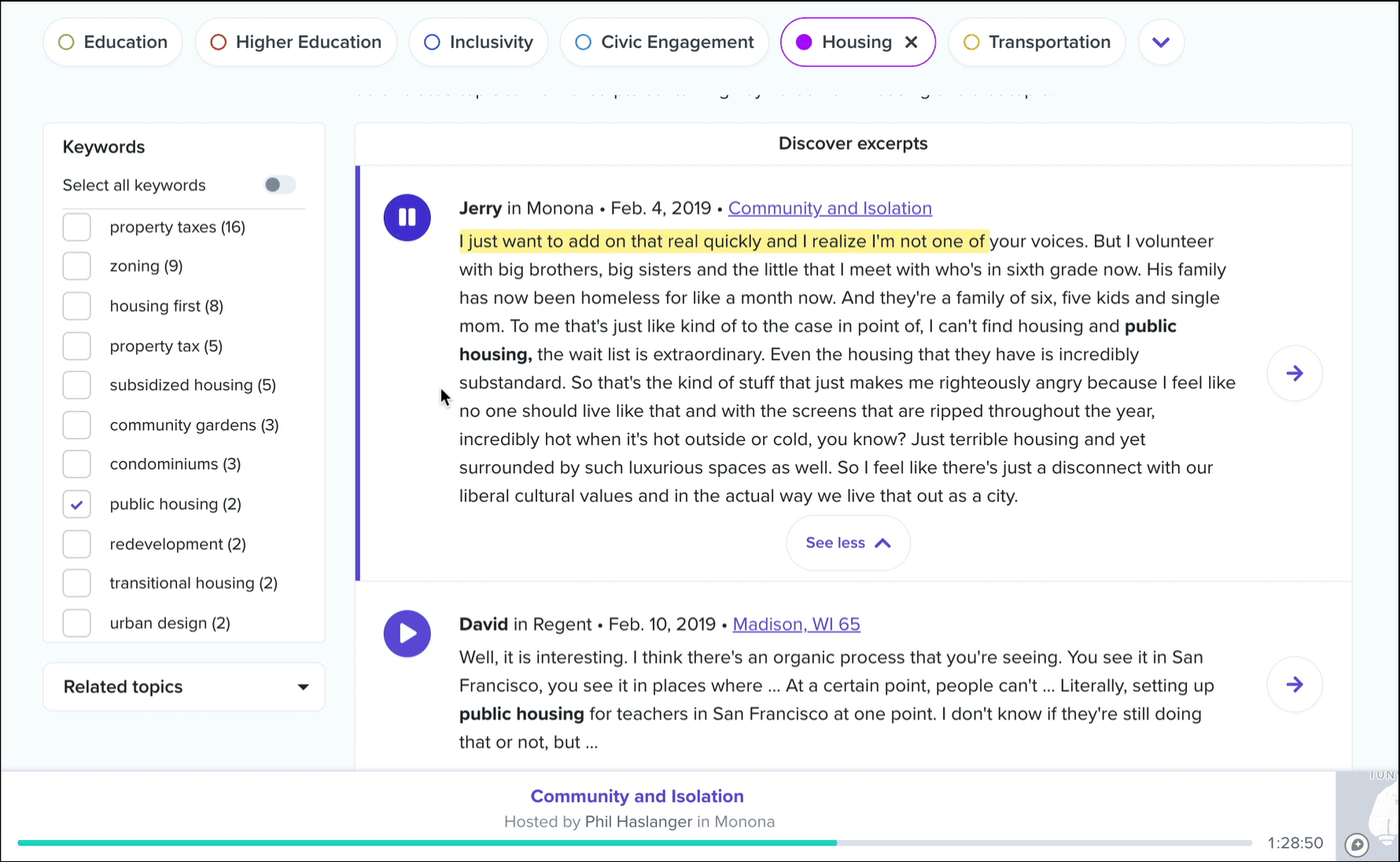
In addition, you’ll see a dropdown called related topics. Select any topic from this list to view conversation excerpts that contain keywords from both topics. This list is ordered by frequency of cooccurrence, and in each excerpt we’ll color code the keywords by parent topic.
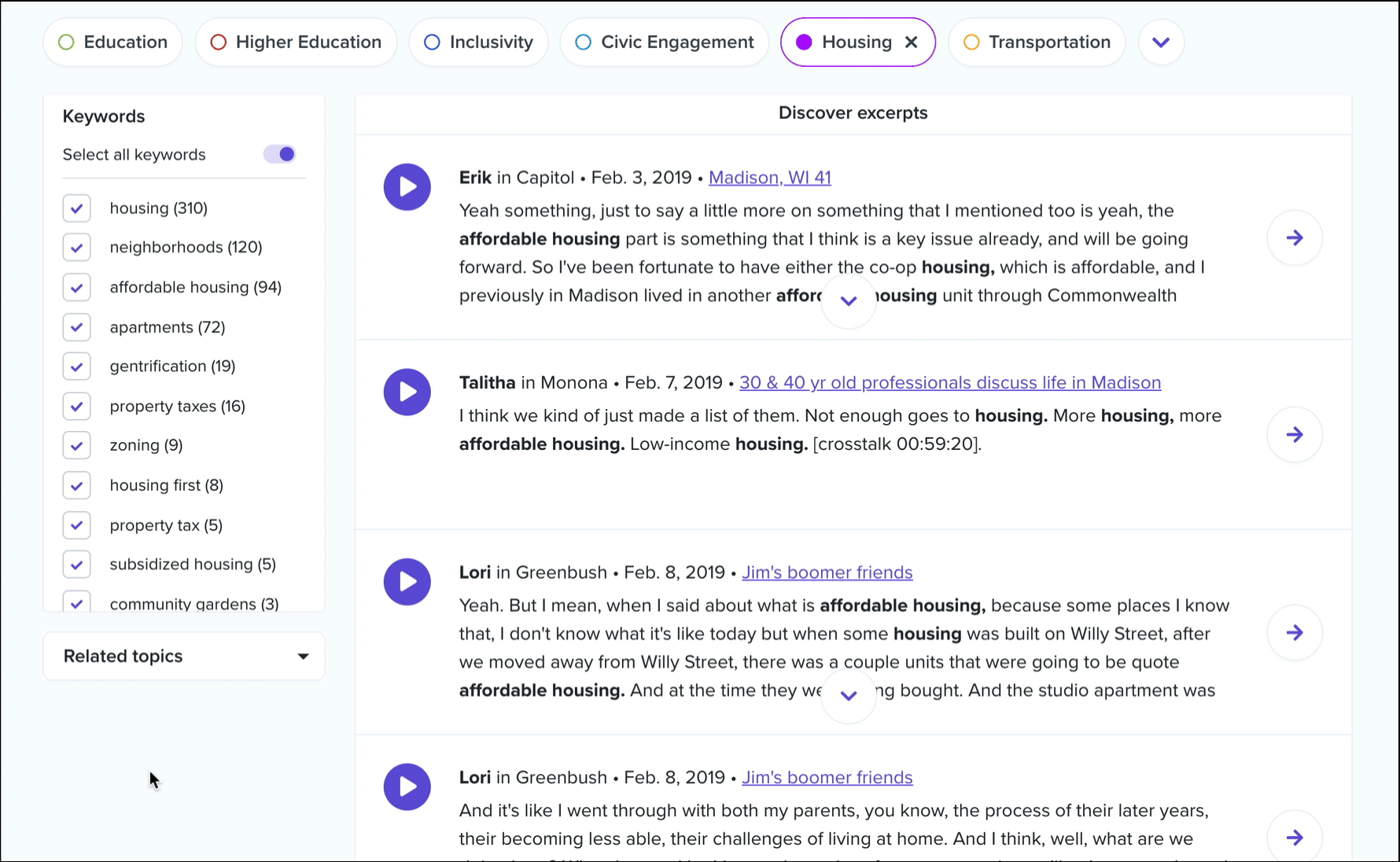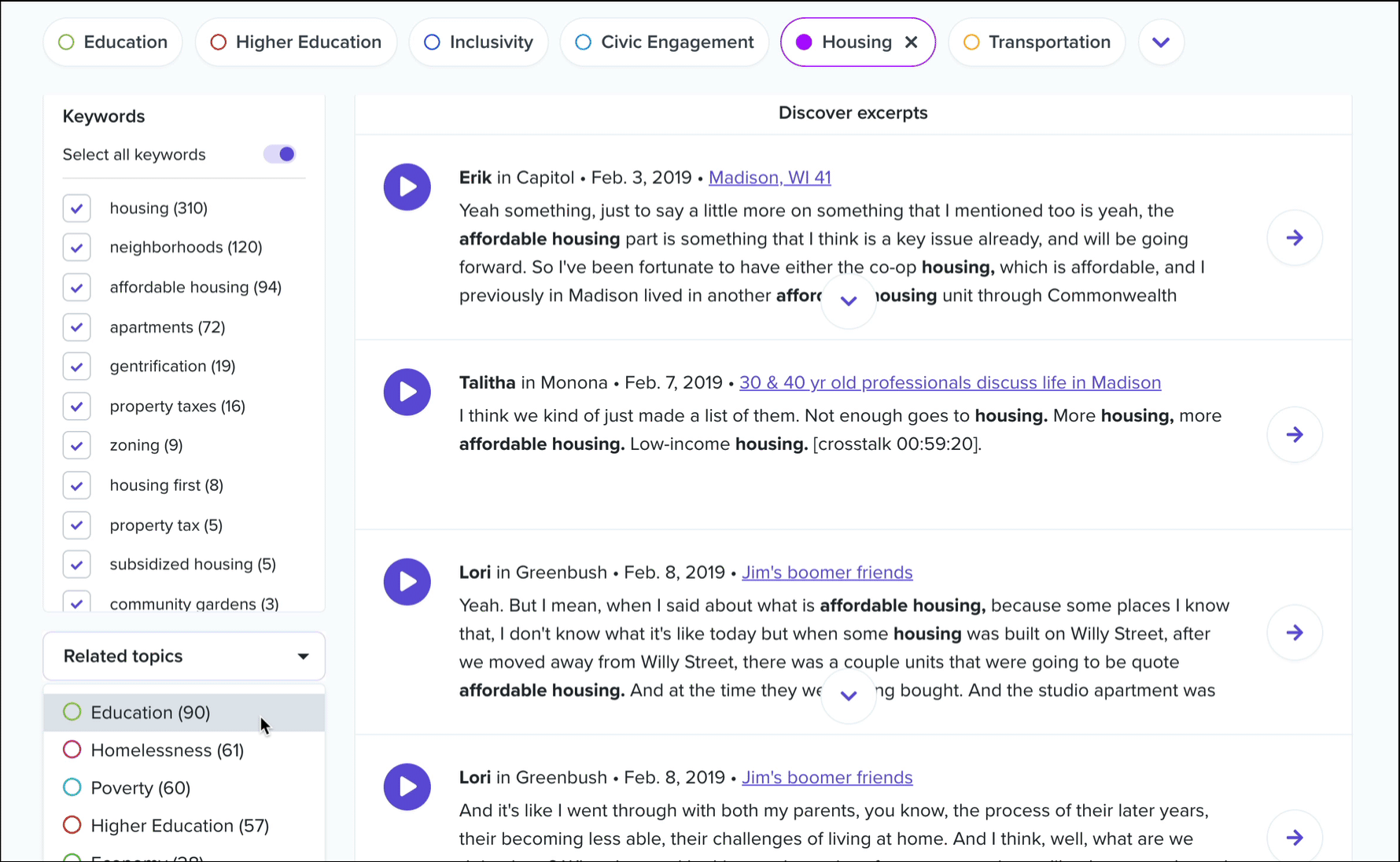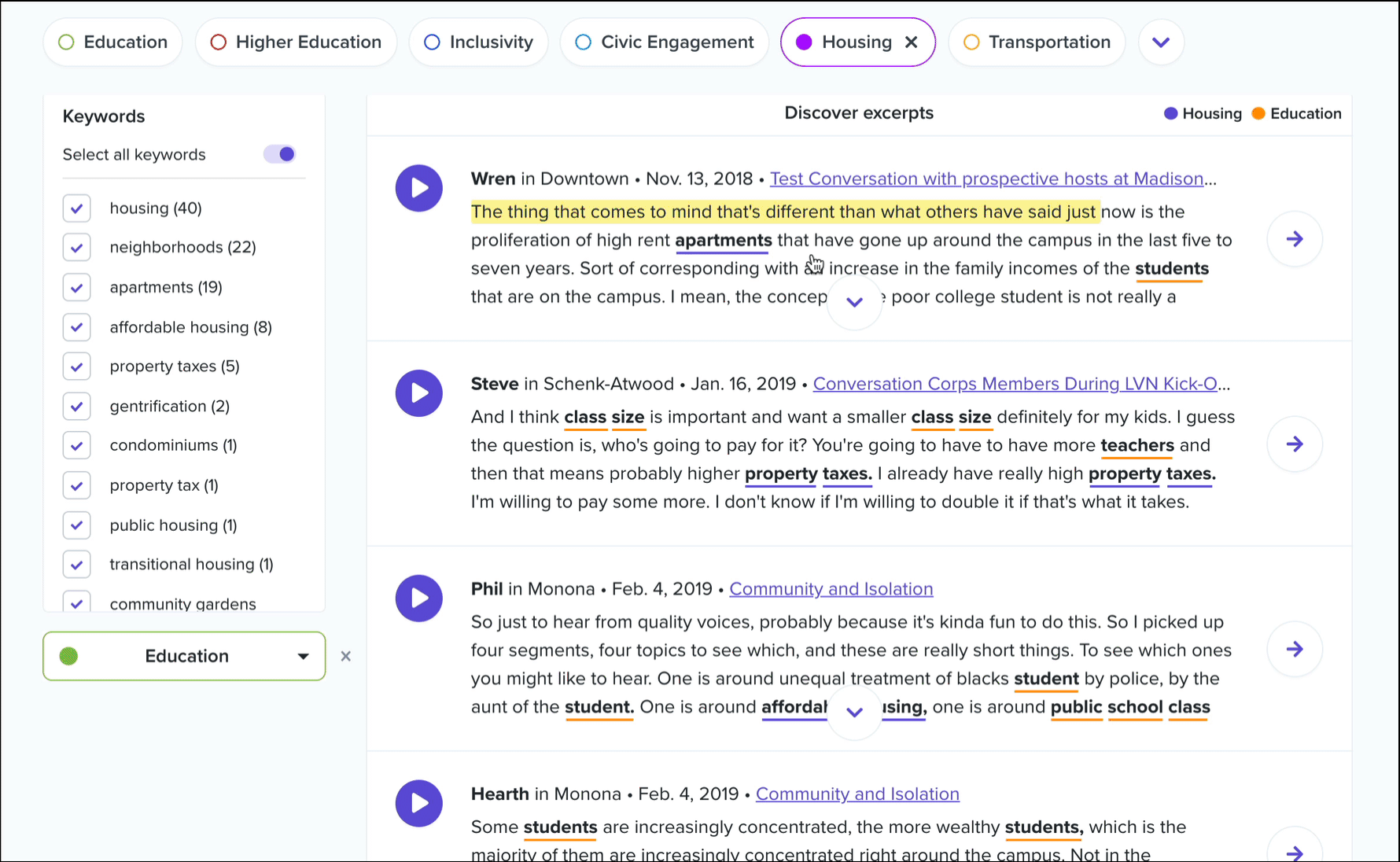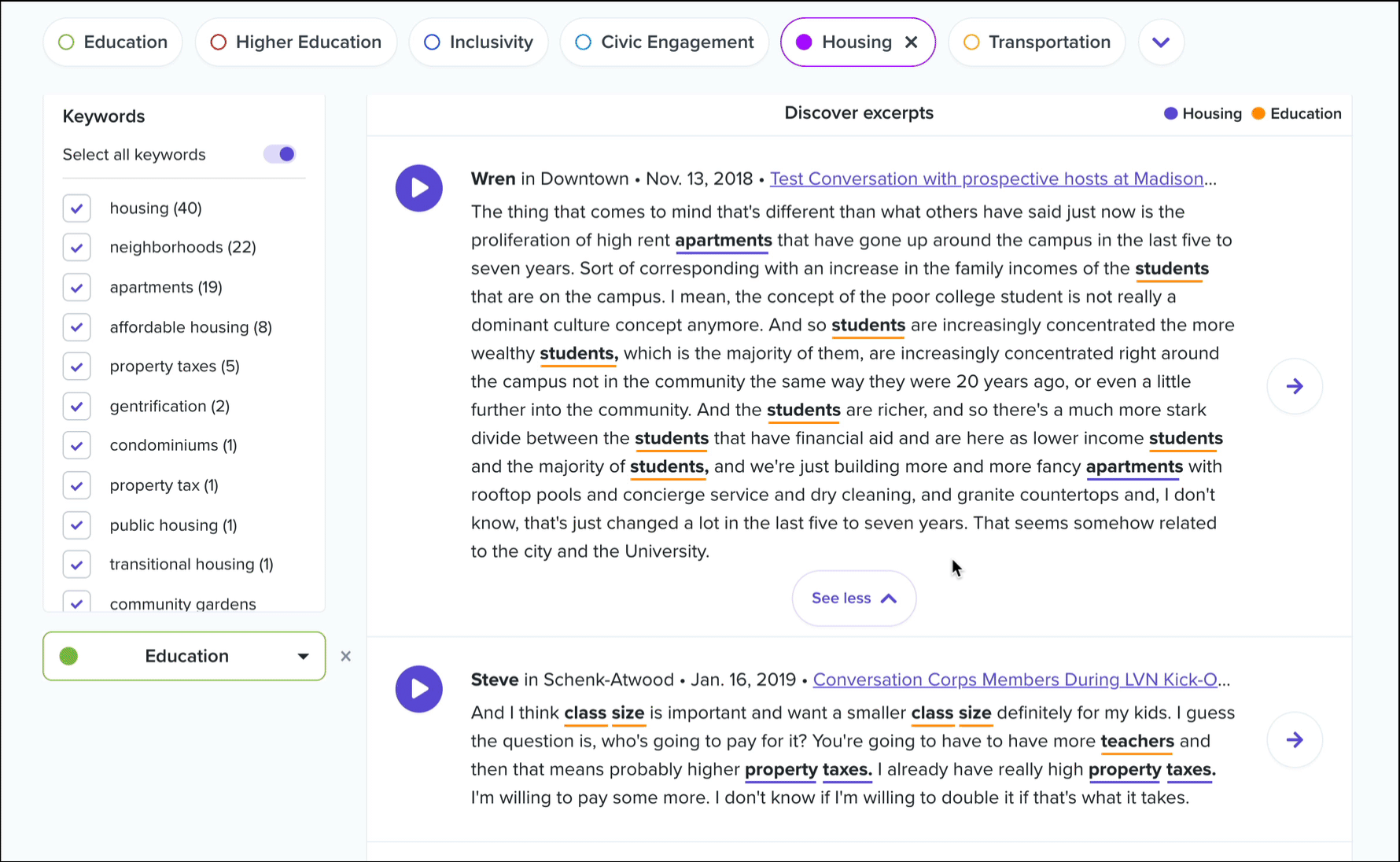
Once you’ve found an excerpt that you’d like to save for later or share with others, you’ll want to turn it into a highlight. Clicking the “Go to conversation” button will take you directly to that excerpt in its parent conversation. We recommend listening to what happened in the conversation before and after that excerpt to get a better understanding for the context in which it was spoken… there may have been an amazing story that was told just before! Then, simply select the text in the transcript and create your highlight as usual!
We’re excited to be releasing this first foray into collection-level insights later this month. In the meantime we welcome any thoughts, feedback, or questions you may have. Just send a note to help@lvn.org and we’ll get right back to you!
p.s. If you’d like to help us improve our sense-making technology, we’re currently hiring a software engineer.
